Ejemplos practicos
A continuación mostraremos algunas situaciones a las que nos enfrentamos al manejar estos archivos, y como la herramienta nos puede ayudar a solucionarlas. Son ejemplos prácticos que permiten entender el funcionamiento y la utilidad de la herramienta en forma practica y en algunos casos utilizan mas de un comando.
Para conocer mas acerca de los diferentes comandos expuestos, podemos visitar la sección correspondiente a cada uno de los comandos utilizados aquí, y presentados mas adelante en este mismo documento en la sección Comandos.
Identificar y obtener información de los archivos
Muchas veces nos encontramos con una lista de archivos de diferentes tipos, y por la nomenclatura nos es difícil determinar el contenido. Simplemente listando el directorio no podemos saber el tipo de información que contienen, y menos aun, el formato del archivo.
A modo de ejemplo, veamos el contenido de un directorio con archivos para explicar esta situación con un ejemplo:
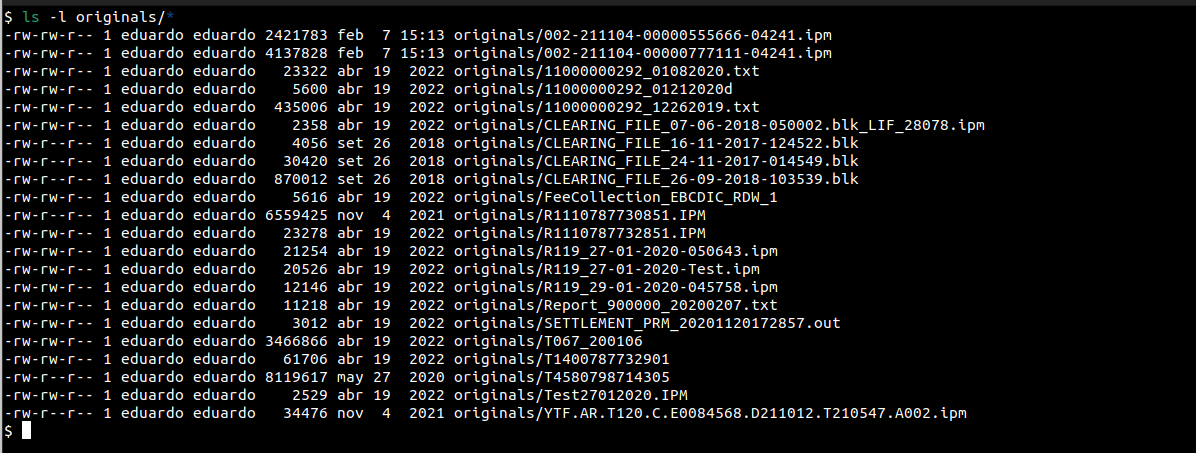
Podemos ver una serie de archivos, algunos nombres nos pueden resultar familiares, pero las extensiones son variadas y no todos cumplen con una nomenclatura en particular. Ademas, tampoco sabemos la codificación utilizada (si están en ASCII o en EBCDIC), si son archivos con registros de longitud fija, variable, o delimitados, o incluso si están en bloques o no (MasterCard suele enviar los archivos en bloques).
Veamos ahora como utilizaría la herramienta para determinar esto. Cuando la invocamos sin especificar ningún comando, se asume que estamos usando el comando IDENTIFY
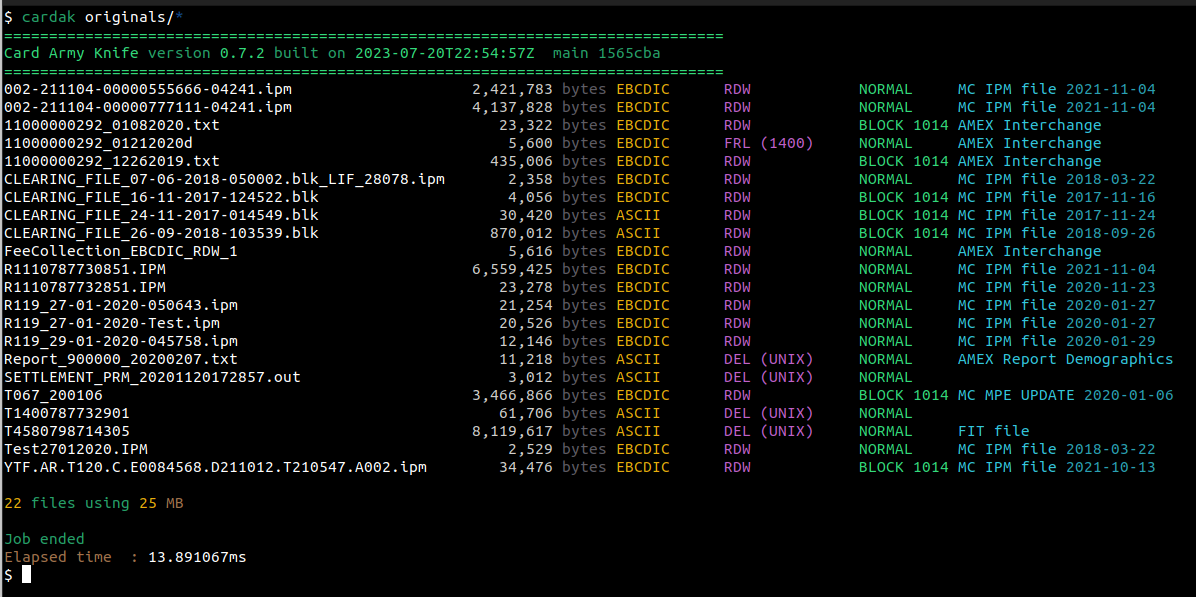
La información que vemos es la siguiente: primero, el nombre del archivo, luego su tamaño en bytes, la codificación utilizada (ASCII o EBCDIC), el tipo de registros (RDW – Registros de largo variable, FRL – Registros de longitud fija y su largo, DEL – Delimitados, y si se usan los delimitadores de Unix o de Windows), y si el archivo esta en bloques o no.
Ademas se muestra, en caso de ser posible, de que tipo de archivo se trata. Vemos que en su mayoría son archivos IPM de MasterCard, pero tenemos también archivos de MPE, de AMEX e incluso de VISA
Para los archivos IPM y MPE de MasterCard, se nos muestra la fecha que viene indicada en el Header del archivo.
Si bien en estos momentos la herramienta esta desarrollada para trabajar principalmente con archivos de IPM de MasterCard, hay algunas operaciones que funcionan con otros tipos de archivos, como por ejemplo lo que veremos mas adelante que es el cambio de formato.
A continuación, y a efectos de mostrar ejemplos concretos, vamos a trabajar con los siguientes archivos:

Veamos de qué se tratan estos archivos:
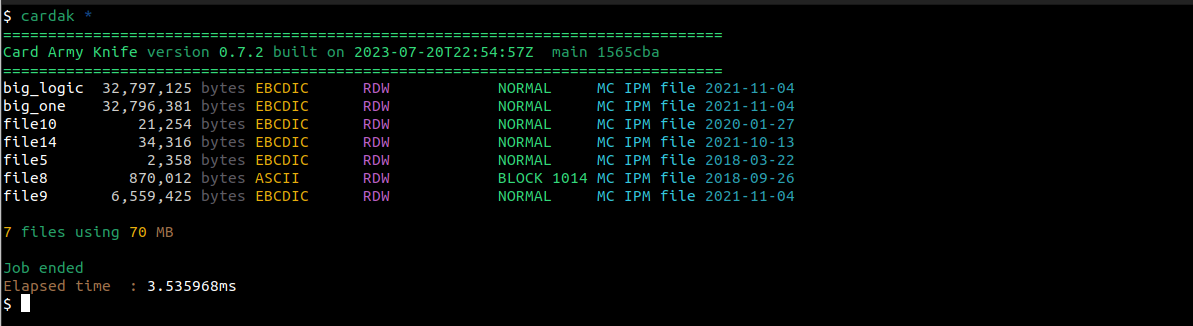
Son todos archivos IPM de MasterCard, y hay archivos en ASCII, en EBCDIC, con y sin bloques. Todos los archivos IPM contienen registros de longitud variable (o RDW)
Esta vista es compacta, con los datos de cada archivo en una sola linea. Podemos tener una vista diferente si especificamos solo un archivo, como por ejemplo file8, especificando el nombre del archivo como parámetro, de esta forma:
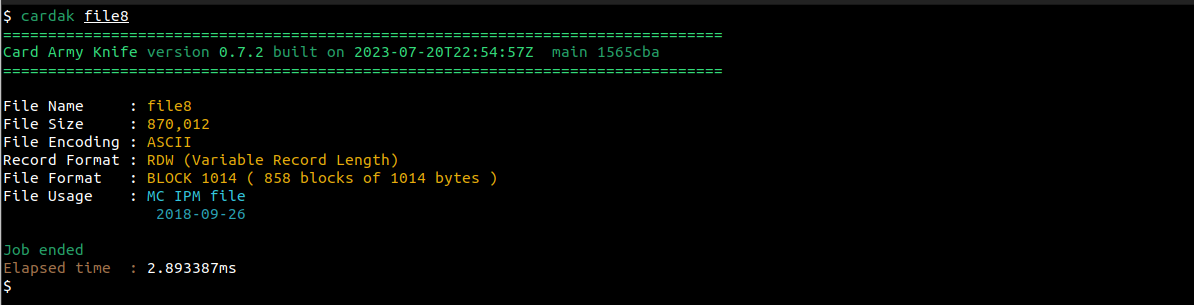
Esta información se obtiene a partir de una muestra de los primeros 10Kb del archivo (o el archivo completo si su tamaño es menor que eso), por lo que el proceso es sumamente rápido.
Si quisiéramos tener mas información, podemos especificar el flag --analyze (-a), que leerá el contenido total de los archivos y nos podrá brindar otros datos. Por ejemplo:
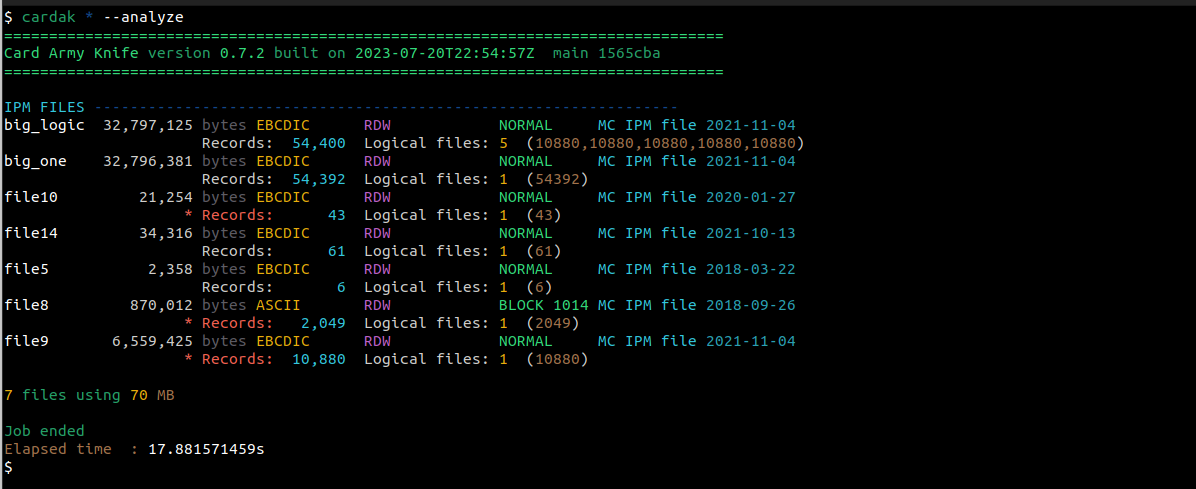
En este caso, se agrega una linea donde podemos ver la cantidad de registros que contiene cada archivo, la cantidad de archivos lógicos, y la cantidad de registros por cada archivo lógico que contenga. En el caso del primer archivo, vemos que contiene 5 archivos lógicos, cada uno con 10880 registros (todos tienen la misma cantidad porque el archivo fue creado con fines demostrativos, uniendo 5 veces el mismo archivo)
Vemos que algunos contiene la palabra “Records” en color rojo y con un asterisco delante. Esto significa que se encontraron algunos errores al procesar el archivo.
Para investigar un poco mas, indicaremos como parámetro solamente el nombre del archivo a verificar, lo que nos mostrara información mas detallada. Veamos que problemas contiene el archivo file10
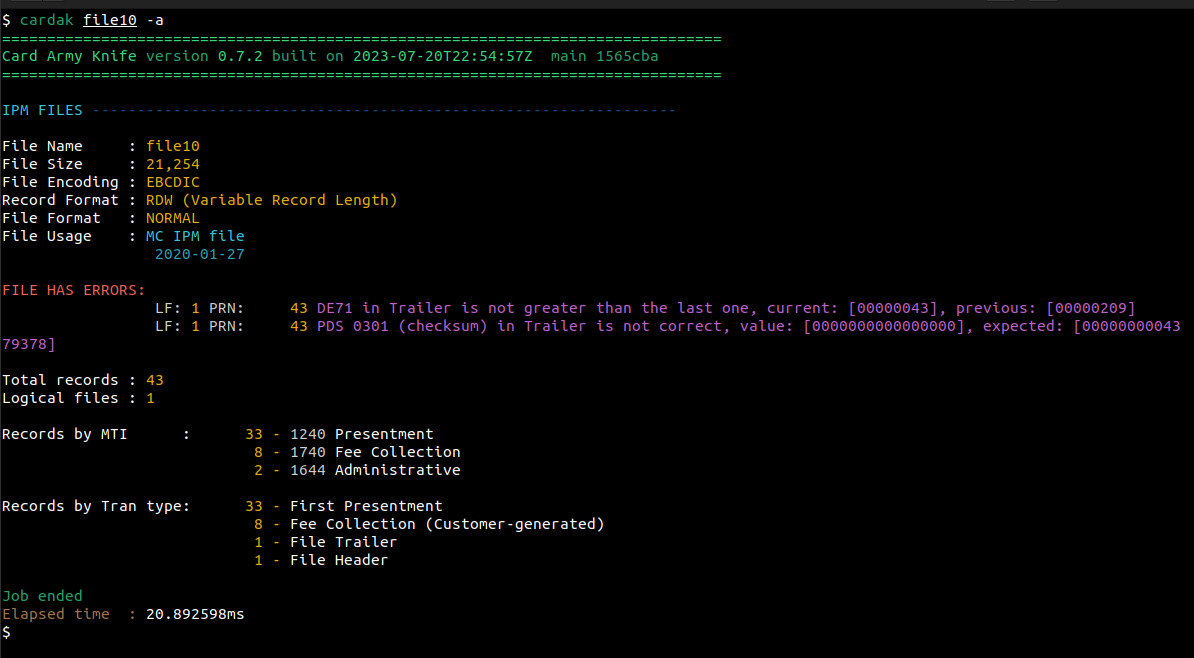
Vemos que el archivo contiene errores en el archivo lógico numero 1 (LF: 1), y en particular en el registro físico numero 43 (PRN: 43) que es el trailer del archivo. Se nos indica que el campo DE71 (indicador de numero de linea dentro del archivo) no cumple con el requisito que sea mayor al anterior. También se nos indica que el campo PDS0301, que contiene el checksum los los importes, no es correcto.
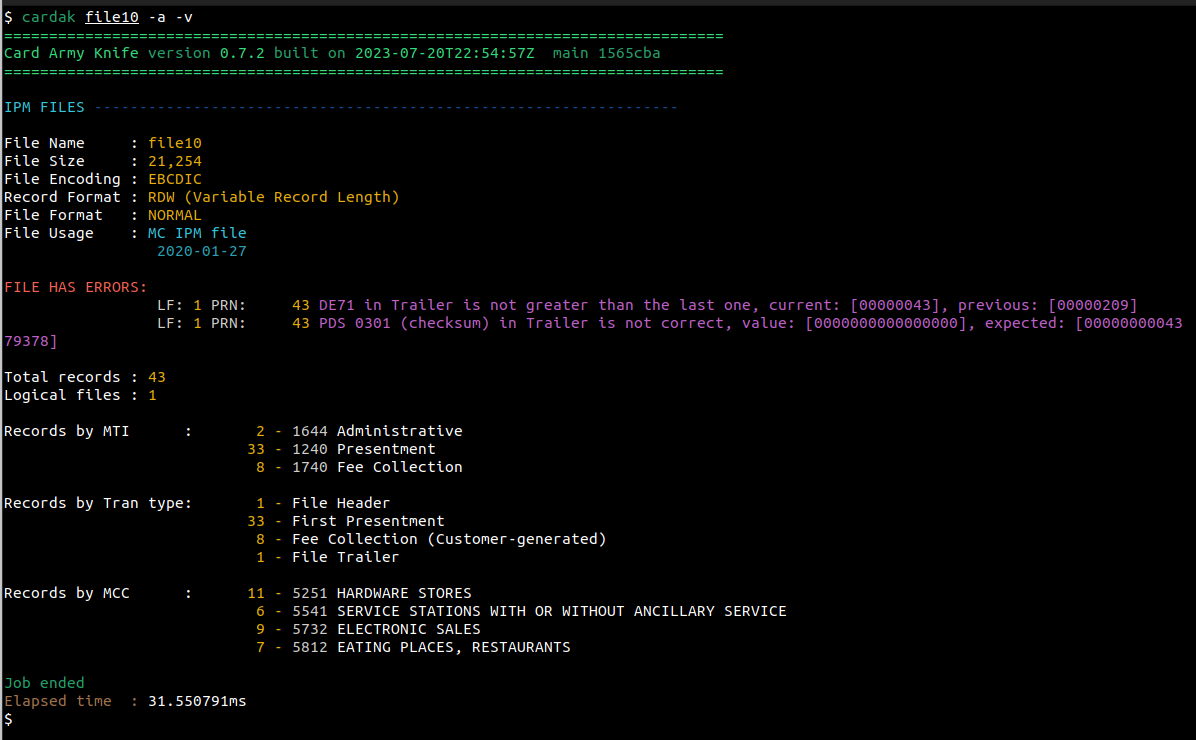
Ademas se nos brinda información estadística, por ejemplo, la cantidad de registros por cada MTI, o la cantidad de registros por cada tipo de transacción. Si ademas agregáramos el flag --verbose (-v), se nos mostraría la cantidad de registros encontrados por cada valor de MCC
Validar los archivos en busca de errores
Esto es útil para ser utilizado en un proceso automatizado, donde es ventajoso tomar acciones antes de procesar un archivo si detectamos que este contiene errores. Se pueden validar luego de ser generados y antes de ser transferidos a fin de evitar rechazos de la marca ante errores detectables, ya que después de determinada cantidad de rechazos, la marca puede aplicar multas económicas.
La validación puede hacerse de un archivo en particular o de una lista de archivos. La herramienta devuelve un código de error al sistema operativo en caso de detectar algún error, o un valor cero en caso que todos los archivos pasen la validación, lo que permite automatizar fácilmente el chequeo y posterior acción.
Veamos como funciona. Primero, validaremos los archivos cuyo nombre son file*
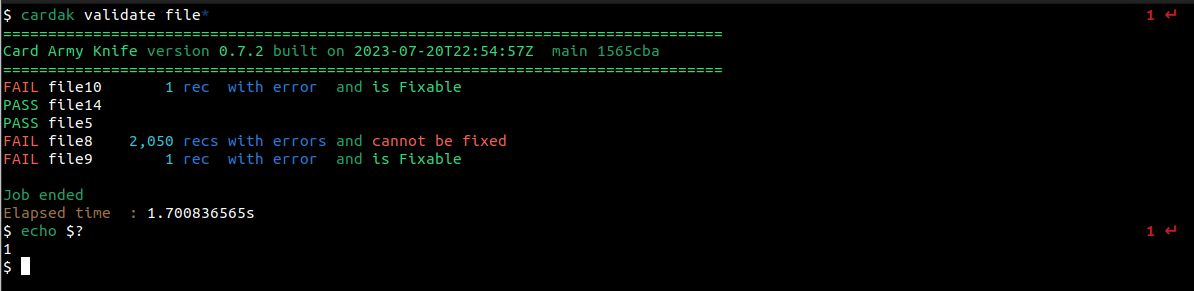
Vemos que hay dos archivos que pasan las validaciones, y tres que fallan. Vemos la cantidad de registros que contienen errores, y un mensaje que nos indica si los tipos de errores encontrados pueden ser corregidos automáticamente o no. Vemos que el valor devuelto al sistema operativo es 1, lo que indica que se encontraron errores.
Una salida alternativa es agregar el flag --silent (-z) para analizar la salida y tomar acciones en forma automática.

El flag --silent omite toda salida por consola, excepto los resultados. Como vemos, la salida es una linea por archivo, que contiene 4 secciones separadas por el carácter “:”. La primera indica si la validación ha fallado o no, la segunda es el nombre del archivo, la tercera es la cantidad de registros con errores (en caso de haberlos), y la cuarta indica si los errores encontrados pueden ser corregidos automáticamente o no.
Continuando con su utilidad para las automatizaciones, podemos especificar si queremos obtener solamente la lista de los archivos sin errores o aquellos que contienen errores. Por ejemplo:

De esta forma, podemos analizar la salida y mover solamente aquellos archivos que sean correctos o que contengan errores.
Volviendo a la validación, podemos obtener información mas detallada de los errores encontrados, agregando el flag --verbose (-v) de esta forma:
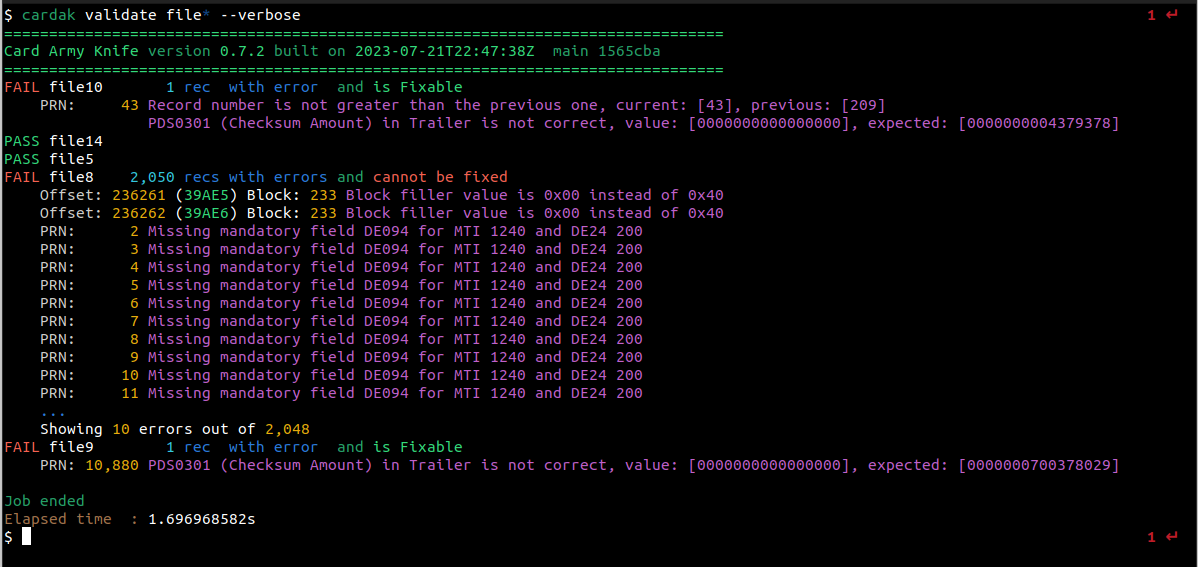
Vemos que el archivo file10 contiene el error en el trailer (que puede ser corregido), y que file9 contiene un error también en el trailer ya que el checksum no contiene el valor esperado. Este error también se puede corregir automáticamente.
Sin embargo, vemos que file8 contiene varios errores de diferente tipo. Los dos primeros errores son de formato del archivo, y nos esta indicando que en las posiciones 236261 y 236262, se encontraron bytes con el valor 0x00 cuando lo correcto seria que contuvieran el valor 0x40. Estos dos errores pueden ser corregidos, pero vemos que ademas hay otros errores (se muestran solo los primeros 10 errores), 2048 en total, donde vemos que para esa combinación de MTI (1240) y Function Code DE24 (200), el campo DE094 (Transaction Originator Institution ID Code) es mandatorio, pero no esta presente. Este tipo de errores no se pueden corregir automáticamente ya que no podemos saber que valor deberíamos poner en este campo sin un análisis de estos casos en particular.
Corregir errores automáticamente
Algunos errores pueden ser corregidos automáticamente. Por ejemplo, los números de registro dentro del archivo (deben tener valores ascendentes y cada header de un archivo lógico debe comenzar con el valor 1), o el checksum del trailer, o que los caracteres de relleno de los bloques (el estándar especifica el valor 0x40 pero puede llegar a venir otro valor, como por ejemplo 0x00), son todos errores que pueden ser corregidos recalculando los valores.
Otro tipo de errores, como ser campos que faltan, o errores físicos del archivo (por ejemplo un largo que este incorrecto, o caracteres no autorizados en campos), seguramente no puedan ser corregidos en forma automática, pero la herramienta ofrece otras formas de corregirlos en forma manual (Ver la sección TUI - Text User Interface )
Habíamos visto previamente que el archivo file10 contenía dos errores y que era posible corregirlos automáticamente. Para eso utilizaremos el comando FIX
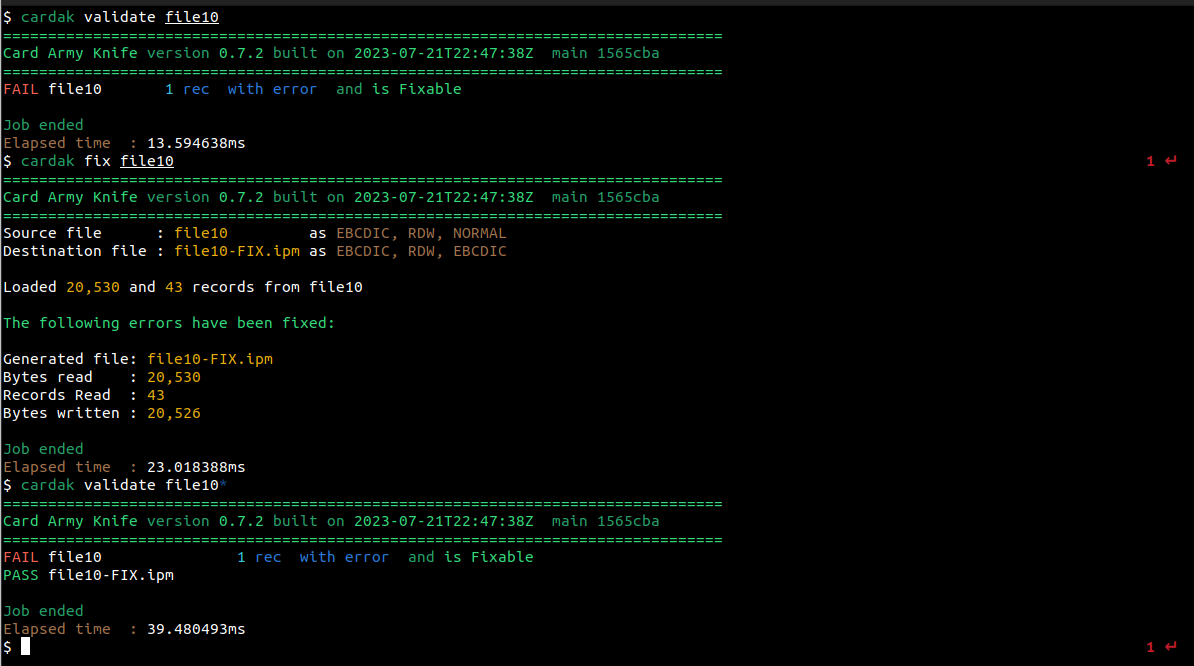
El archivo corregido mantiene el nombre del archivo original, pero le agrega “-FIX.ipm” al final. Se agrega esa extensión porque el comando FIX solo esta disponible para archivos de tipo IPM
Podemos aplicar este comando a un archivo a la vez, o a una lista de archivos, pero solo se corregirán los archivos detectados como MasterCard IPM
Cambiar el formato de los archivos
Algunas veces, y especialmente durante los periodos de certificación, el formato de los archivos generados no coinciden con el formato esperado por la marca y viceversa. En algunos sistemas es sencillo (aunque inconveniente) cambiar la configuración para poder procesarlos correctamente.
En estos casos, la herramienta nos permite, fácilmente, cambiar el formato de un archivo a otro deseado.
Por ejemplo, veamos el formato del archivo file14:
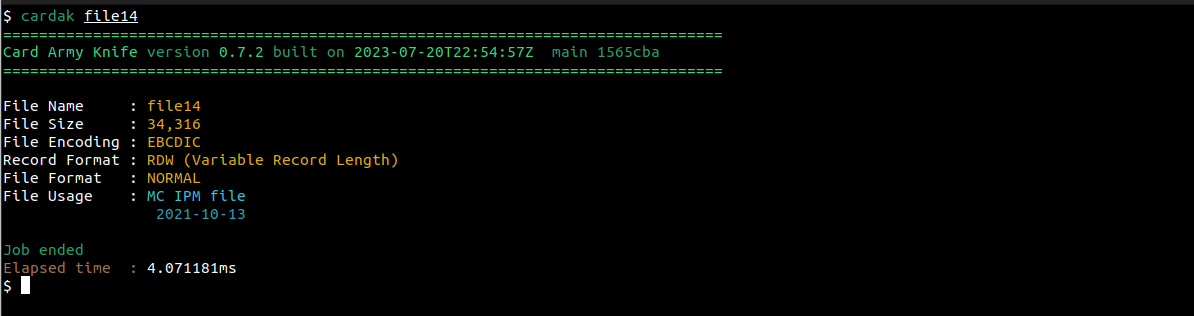
Es un archivo codificado en EBCDIC, y no esta en bloques de 1014. Supongamos que queremos convertirlo en un archivo codificado en ASCII y en bloques de 1014.
Esto lo podemos hacer fácilmente de esta forma:
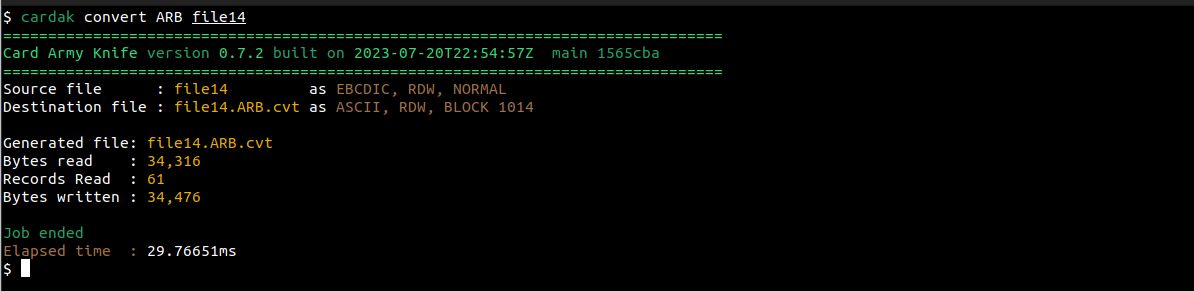
Utilizamos el comando CONVERT, especificando el formato (son tres letras que identifican codificación, tipo de registro y formato de archivo) – para mas detalles ver la descripción del comando CONVERT en la sección correspondiente.
El archivo generado convertido queda con el mismo nombre del original, pero agregándole al final las tres letras utilizadas para el formato de conversión, y la extensión .cvt
Este comando funciona para varios tipos de archivos, no solo los IPM de MasterCard. Podemos por ejemplo, convertir los archivos de MPE y algunos otros tipos de archivo.
Este comando se puede utilizar con un archivo a la vez, o una lista de archivos a los cuales se les aplicara la conversión solicitada de una sola vez.
Búsqueda de datos en archivos IPM
En Linux (y Unix en general), solemos disponer del comando grep para realizar búsquedas en archivos. Esto funciona muy bien cuando los archivos que contienen los datos son de texto plano, lo cual no es el caso para archivos IPM
Por ejemplo, sabemos que en alguno de estos archivos hay compras en un local llamado “Carpinteria”, pero no sabemos en cual de ellos están esas transacciones.
Primero, intentemos utilizar el comando grep del sistema:
 Como podemos observar, no obtenemos ningún resultado, y grep nos devuelve el valor 1 indicando que no pudo efectuar búsquedas en archivos “binarios”
Podemos, por supuesto, abrir el archivo con un editor hexadecimal y realizar ahí la búsqueda. Probemos ver
Como podemos observar, no obtenemos ningún resultado, y grep nos devuelve el valor 1 indicando que no pudo efectuar búsquedas en archivos “binarios”
Podemos, por supuesto, abrir el archivo con un editor hexadecimal y realizar ahí la búsqueda. Probemos ver
Podemos, por supuesto, abrir el archivo con un editor hexadecimal y realizar ahí la búsqueda.
Probemos ver si podemos utilizar hexdump desde la linea de comandos:
No parece contener algo que sea facilmente legible, pero cual es el problema? Vemos que la codificación es EBCDIC, por lo que si bien podemos ver los valores de los bytes, no contienen una representación sencilla en ASCII. Claro que podríamos convertirlo primero a ASCII y luego usar hexdump, pero cuando tenemos muchos archivos, eso no es una opción muy practica.
Intentemos utilizar otra herramienta, en este caso una herramienta grafica (ya que en Windows también existen editores en hexadecimal gráficos):
Ahora, al cambiar la codificación a EBCDIC, comenzamos a ver valores que pueden llegar a identificarse. Sin embargo, esta opción requiere ir abriendo uno por uno los archivos para efectuar las búsquedas, y cuando necesitamos buscar algo mas especifico, que no sea solamente una cadena de caracteres, la situación tampoco mejora mucho.
Veamos entonces como podemos utilizar la herramienta para realizar búsquedas en archivos IPM.
Como dijimos anteriormente, comenzamos buscando los archivos que contienen transacciones realizadas en un comercio que contiene la palabra “carpinteria” en su nombre. Sabemos que el nombre del comercio viene en el campo DE043, pero vamos a comenzar haciendo una búsqueda global
Para ello, invocamos la herramienta con el comando GREP, indicando primero el criterio de búsqueda y luego el o los archivos donde efectuar dicha búsqueda.
Respecto al criterio, esto es muy flexible, y podemos hacer búsquedas globales (en cualquier parte del registro), en campos específicos (incluidos subcampos), o incluso combinaciones lógicas en las condiciones como OR y AND (para mas información del uso de las condiciones, referirse a la sección correspondiente al comando GREP )
Por el momento busquemos el texto “carpinteria”. Observemos que la busqueda no es case-sensitive
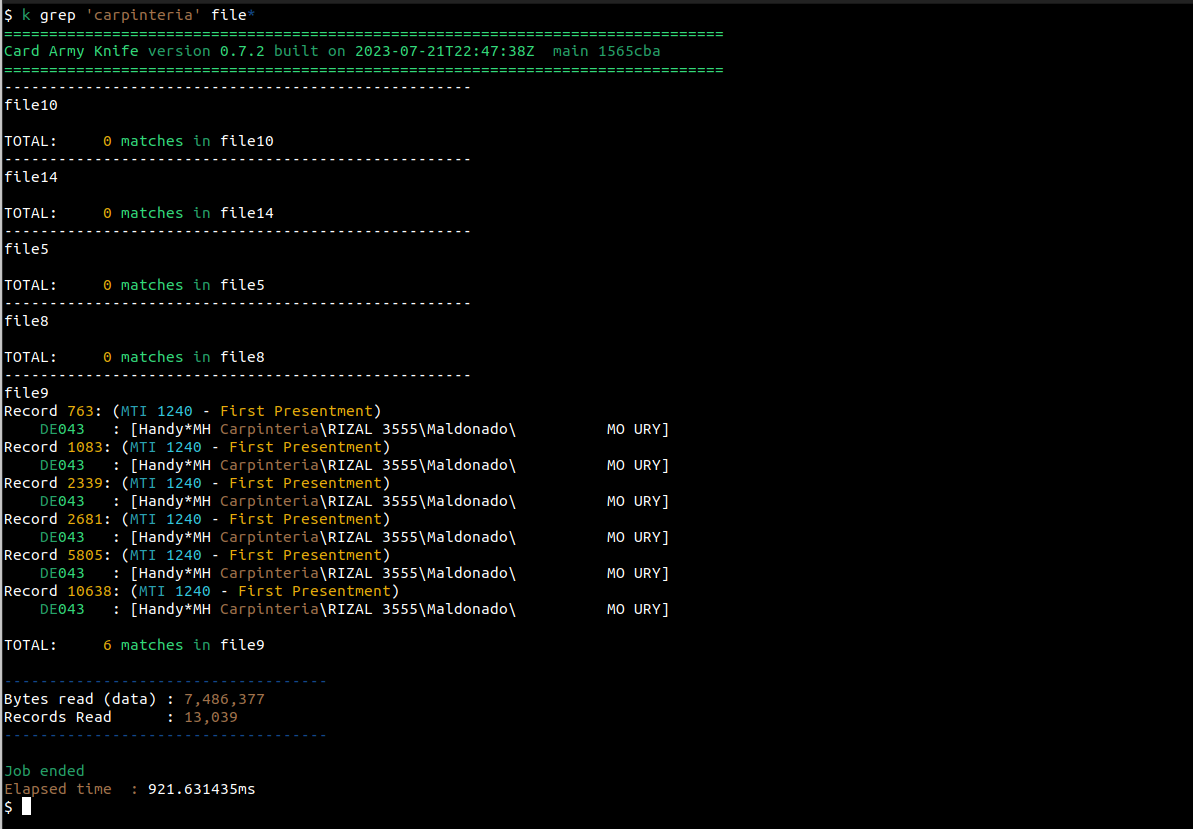
Vemos que en el archivo file9 hay 6 registros que contienen ese texto en el campo DE043. Vemos ademas los números de registro donde esta presente, y vemos también que los 6 registros corresponden a primeras presentaciones.
A partir de aquí podemos centrarnos en mejorar la búsqueda, pero ahora solamente sobre el archivo file9 que es el que contiene nuestra posible transacción buscada.
Por ejemplo, un siguiente paso podría ser que, ademas de mostrarnos los registros donde esta el texto que buscamos, nos muestre, ademas, el contenido de los campos DE004 (Importe de la transacción) y DE012 (Fecha y hora). Para ello podemos agregar el flag -F donde indicamos los campos que queremos mostrar de los registros encontrados, aunque ellos no contengan el valor buscado.
Para indicar los campos, escribimos la lista de campos separados por comas, y podemos indicar si se trata de un Data Element (DE), de un Private Data Subelement (PDS), o incluso si queremos especificar un Subfield de cualquiera de estos. Por ejemplo, la fecha y hora que vienen en el DE012, contiene dos subfields que son, la fecha en el subfield 1, y la hora en el subfield 2. Entonces, en lugar de especificar que queremos el DE12, podemos indicar que queremos el DE12 SF 1 y el DE12 SF 2 por separado.
Para mas información de como especificar los campos y también de como utilizar listas predefinidas, por favor referirse a la sección FILTER
Veamos la salida de este comando:
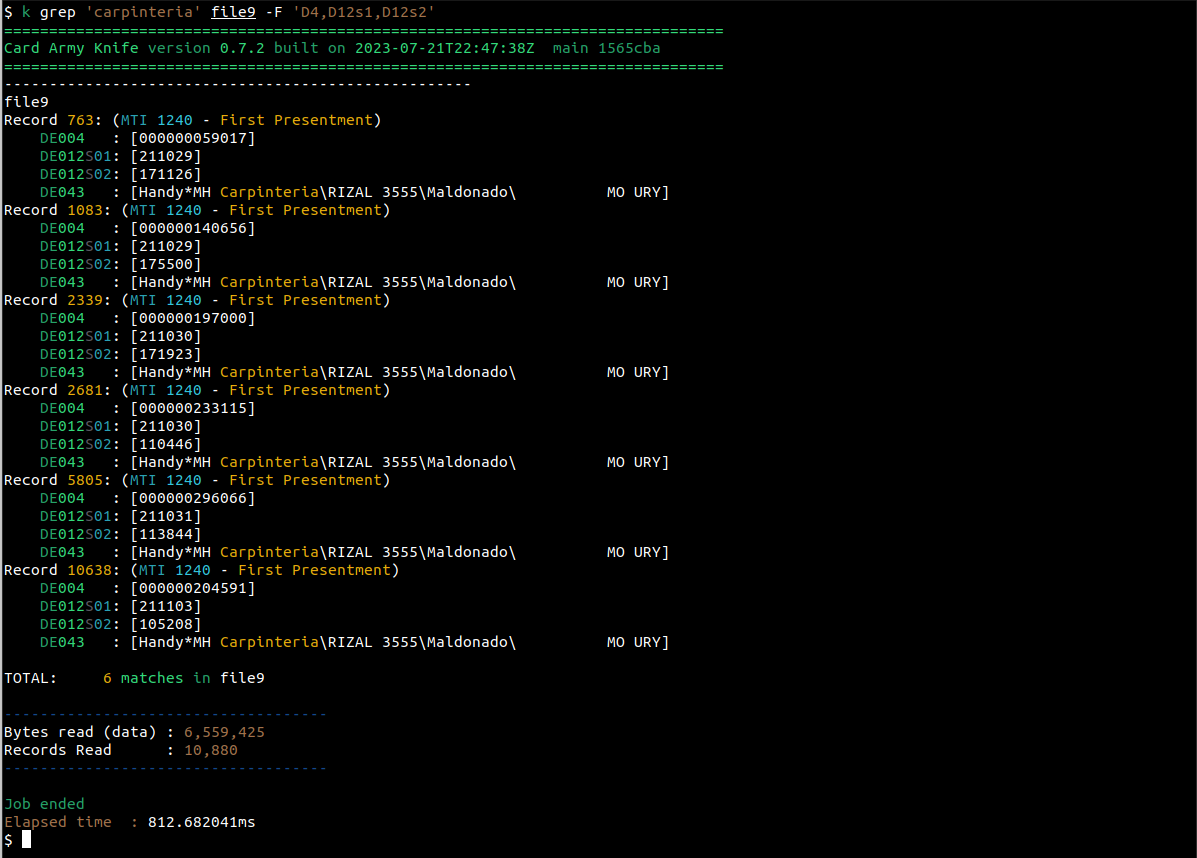
Ahora podemos ver los importes y los horarios en que esas transacciones fueron hechas.
Ahora bien, suponiendo que hay muchos registros que contienen el valor que estamos buscando, pero conocemos algún otro dato de la transacción, podemos ir mejorando el criterio de búsqueda. Por ejemplo, sabemos que la transacción fue hecha en el comercio llamado “carpinteria”, y que el valor de la misma fue de 1970.00
Podemos entonces, buscar ese registro especifico de la siguiente forma:
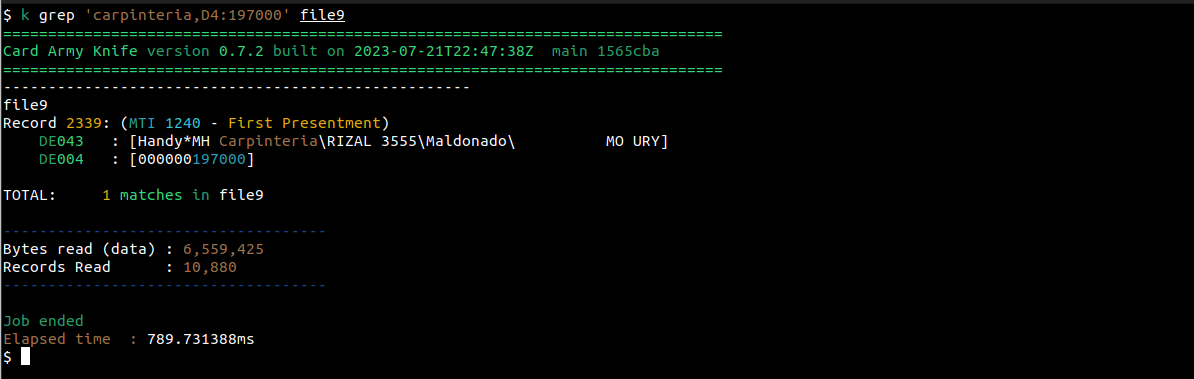
Ahora obtenemos como resultado un único registro, el 2339, que contiene la transacción que estamos buscando.
En este punto seguramente queramos ver todos los datos de la transacción en cuestión. Si bien podríamos especificar la lista de campos a desplegar, existen otras formas mas eficientes.
Para esto, podemos utilizar el comando PRINT. Este comando permite mostrar, en forma amigable, los contenidos de un archivo o de los registros especificados.
Podemos redirigir esa salida a un archivo de texto para poder visualizarla en un editor de texto.
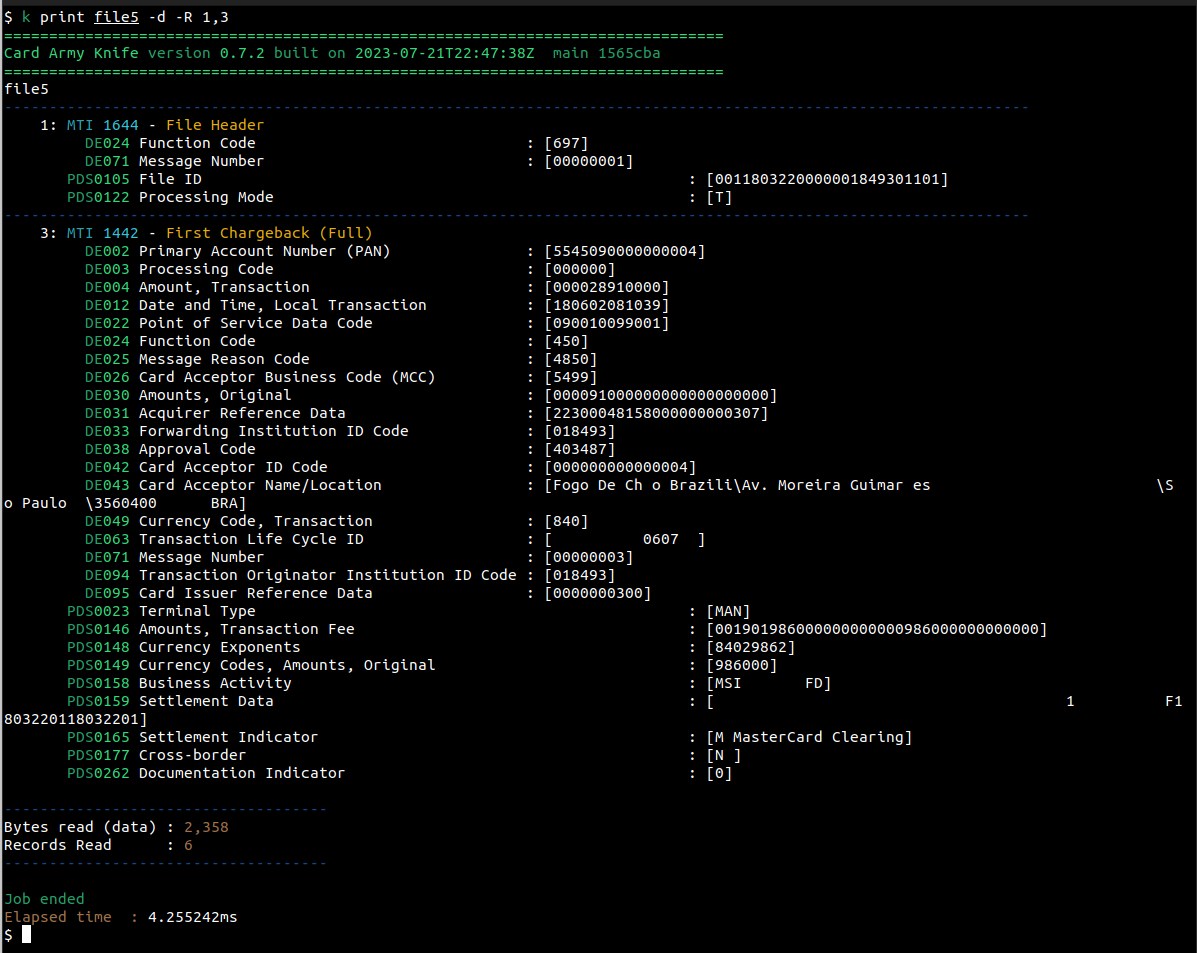
Vamos a ver el contenido del registro encontrado con el comando GREP utilizado anteriormente. Vimos que el registro era el numero 2339, por lo que podemos indicar que queremos ver solamente ese registro
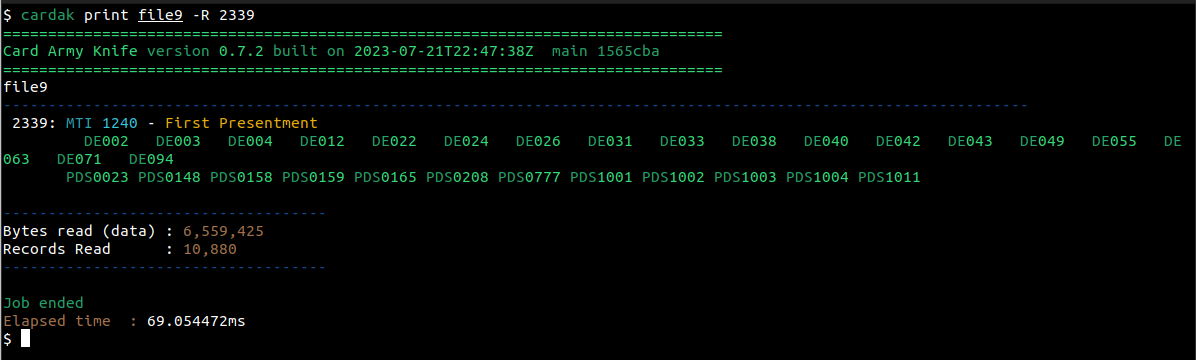
Por defecto, el comando PRINT nos muestra, para cada registro de salida, la lista de campos presentes en el registro (primero los DE y luego los PDS presentes).
Si queremos ver los valores de cada campo, agregaremos el flag --detailed (-d)
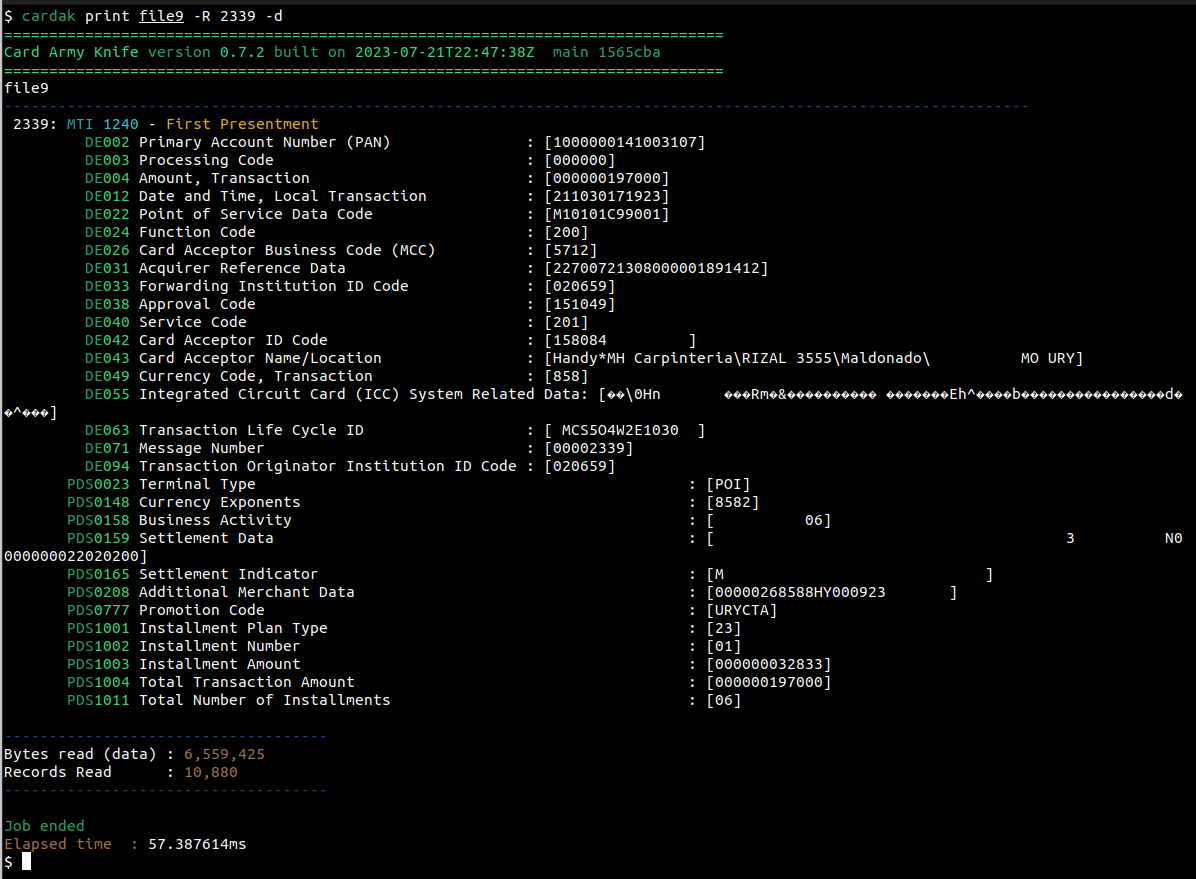
De esta forma veremos la lista de los campos presentes en el registro, su descripción, y el valor correspondiente.
Podemos agregar la opción --subfields (-s) para ver el contenido de cada uno de los subcampos de aquellos que tienen definidos dichos subcampos
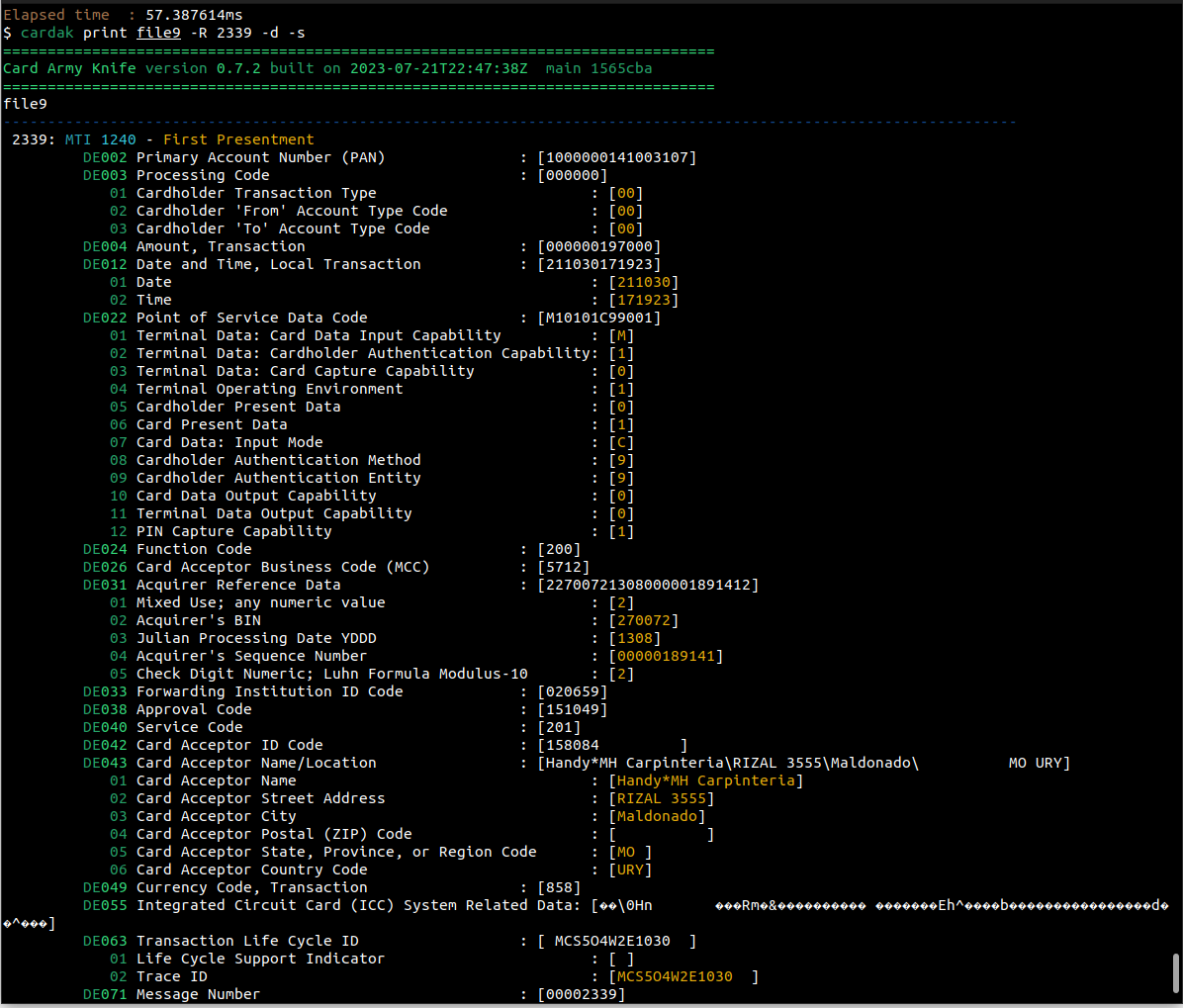
En caso de querer redirigir esa salida a un archivo para ser visto en un editor de texto, es conveniente agregar los flags --silent (-z) o --mono para que la salida se haga sin los caracteres que indican los colores (salida monocromática).
Visualizar el contenido en algún programa externo
Quizás queremos ver o manipular los datos que vienen en un archivo IPM en algún programa externo, ya sea un editor de textos o una planilla de Excel. Esta herramienta permite, fácilmente, imprimir o exportar todos o algunos registros a un archivo que pueda ser utilizado por esos programas externos.
Comenzaremos viendo como podemos ver el contenido de algunos registros de un archivo IPM en un editor de texto
Para eso, utilizaremos el comando PRINT. Con este comando podemos mostrar en un formato legible, el contenido de todo un archivo IPM, o los registros que indiquemos.
Por defecto, el comando PRINT presenta los registros de un archivo, mostrando el numero de registro, el tipo de información que viene en ese registro, y la lista de los campos presentes en el registro.
Si queremos mostrar el contenido de los campos, debemos agregar el flag --detailed (-d). Podemos seleccionar los registros que queremos ver utilizando el flag -R, y para mostrar solamente algunos campos, podemos utilizar el flag -F
Para mas detalles de como utilizar estos flags, ver la sección llamada FLAGS y FILTROS
Podemos utilizar el flag --silent y redireccionar la salida a un archivo, para luego abrirlo con un editor de textos y visualizar los contenidos, hacer búsquedas, imprimir en papel, etc.
Otra opción es utilizar el comando EXPORT. Este comando, por defecto, genera un archivo CSV el cual puede ser abierto con el programa Excel o similar. Ese archivo contiene una primera linea con los nombres de los campos, y en las filas siguientes los valores correspondientes a cada campo.
Se pueden aplicar los mismos filtros para seleccionar los registros y los campos que deseamos queden en el archivo CSV
Hay un flag llamado --console que si esta presente, en lugar de generar un archivo, muestra los contenidos por consola, por lo que podemos redireccionar esa salida a cualquier archivos que deseemos.
Manejar archivos lógicos
Puede ser que si tenemos un archivo que contiene mas de un archivo lógico (MasterCard llama a estos archivos “transmissions”, queramos generar archivos físicos por cada uno de esos archivos lógicos, o viceversa.
Para ello contamos con los comandos SPLIT y JOIN
El comando SPLIT toma el contenido de un archivo, y por cada archivos lógico que se encuentre en el, genera un archivo físico.
El comando JOIN hace lo contrario, toma la lista de archivos físicos que le indiquemos, y genera un nuevo archivo físico generando un archivo lógico por cada uno de los archivos físicos indicados.
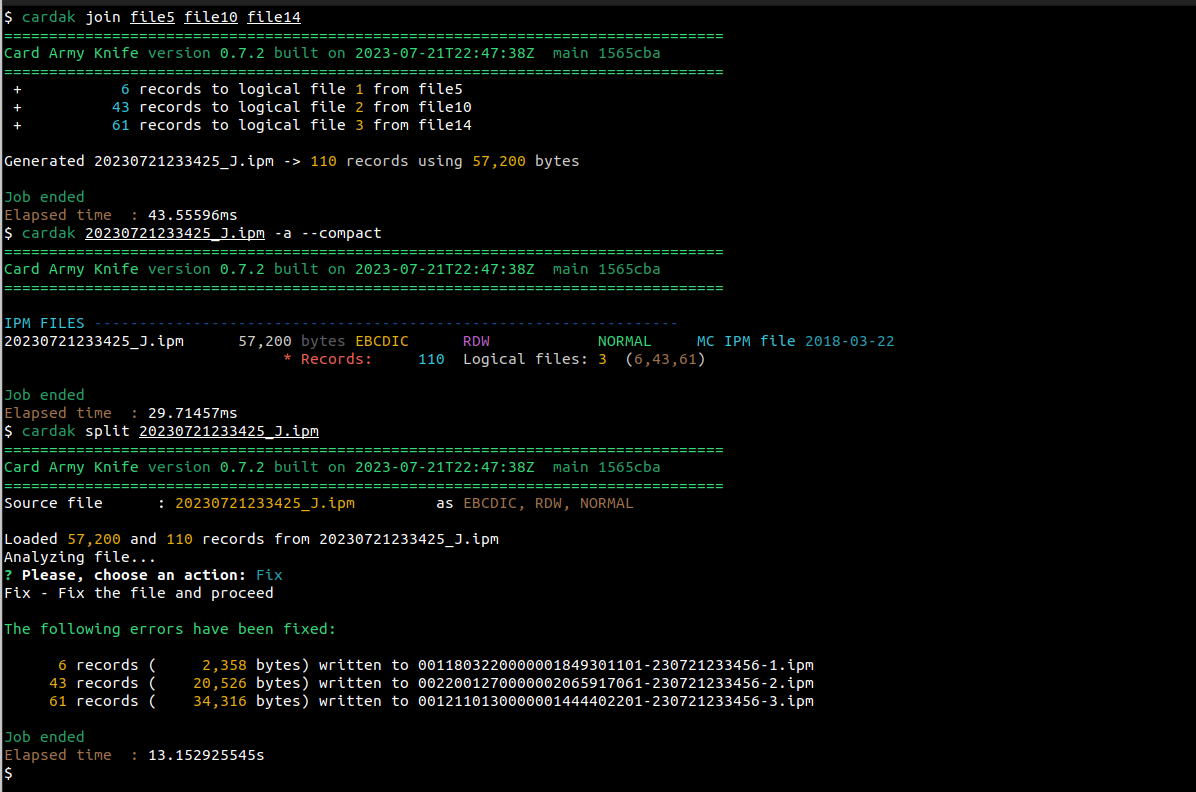
Vemos esos comandos en acción, Primero, hacemos un JOIN de tres archivos (file5, file10 y file14), y se genera un archivo de nombre 20230721233425_J.ipm (es la fecha y hora de generación, mas los caracteres “_J.ipm”
Vemos que efectivamente contiene tres archivos lógicos, conteniendo 6, 43 y 61 registros cada uno)
Luego separamos esos archivos lógicos usando el comando SPLIT. Al intentar separarlos, detecta que hay errores y nos da la opción de cancelar, ignorar o corregir dichos errores. Seleccionamos por ejemplo Fix, y genera tres nuevos archivos físicos cuyos nombres están compuestos por el campo PDS0105 del header de cada uno, seguidos de un guion y la fecha y hora de creación, mas un numero secuencial que identifica al numero de archivo lógico. También les agrega la extensión “.ipm”
Eliminar registros de un archivo
Quizás, por alguna razón, luego de generar un archivo necesitamos quitar algún registro antes de enviarlo, ya sea porque no queremos que esa transacción salga en ese envío, o por un rechazo del archivo enviado anteriormente.
A veces es posible volver a generar el archivo, pero no todos los sistemas tienen una forma sencilla de hacerlo.
Lo primero que debemos hacer es identificar el o los registros que queremos quitar del archivo. Para esto podemos realizar una búsqueda tal como se indica en la sección Búsqueda de datos en archivos IPM
Lo importante aquí es obtener el o los números de registros físicos en el archivo correspondiente.
A modo de ejemplo, utilizaremos el mismo criterio utilizado en el caso tratado anteriormente, de búsqueda de un registro mediante el comando GREP. Vamos a eliminar del archivo file9 el registro correspondiente a la compra en el comercio “Carpinteria” y por un monto de 1970,00

Utilizamos aquí la versión reducida de la búsqueda, ya que sabemos que ese registro esta en ese archivo y ya identificamos el registro, por lo que solo necesitamos conocer el numero de registro (para ello utilizamos --matches y –silent), obteniendo el numero de registro 2339
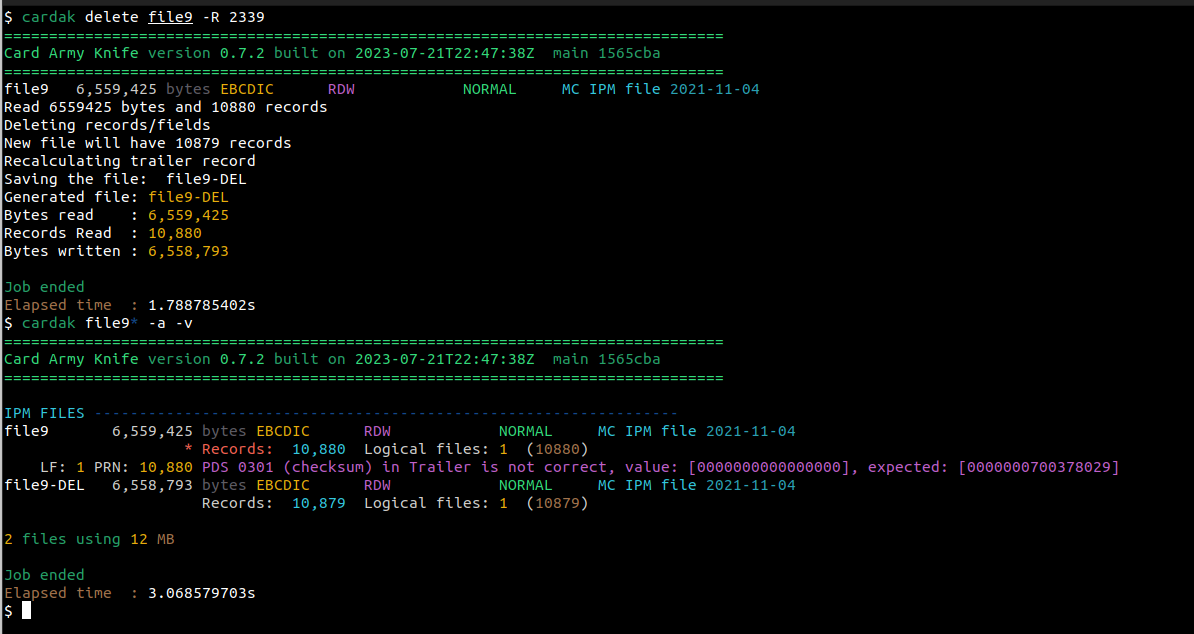
Observamos que se elimino un registro del archivo, el cual originalmente contenía 10880 registros y ahora contiene 10879 registros. Vemos ademas, que el archivo original tenia un error en el trailer, pero el nuevo archivo, al tener que recalcular los valores del trailer, ya soluciona ese problema.
También observamos que el archivo original no se modifica, sino que se genera uno nuevo, por defecto con el mismo nombre del original pero agregándole “-DEL” (podemos especifica el nombre que queremos utilizando el flag --out)
Pero que pasaría si quisiéramos eliminar todos los registros correspondientes al comercio “Carpinteria”? Podemos realizar la operación por cada uno de los registros, o podemos anotar los números de registro encontrados, pero eso puede resultar poco practico si tenemos una cantidad considerable de registros.
Para ello podemos utilizar el flag --last que utiliza el resultado del ultimo comando GREP realizado sobre ese archivo. Veamos como se usa:
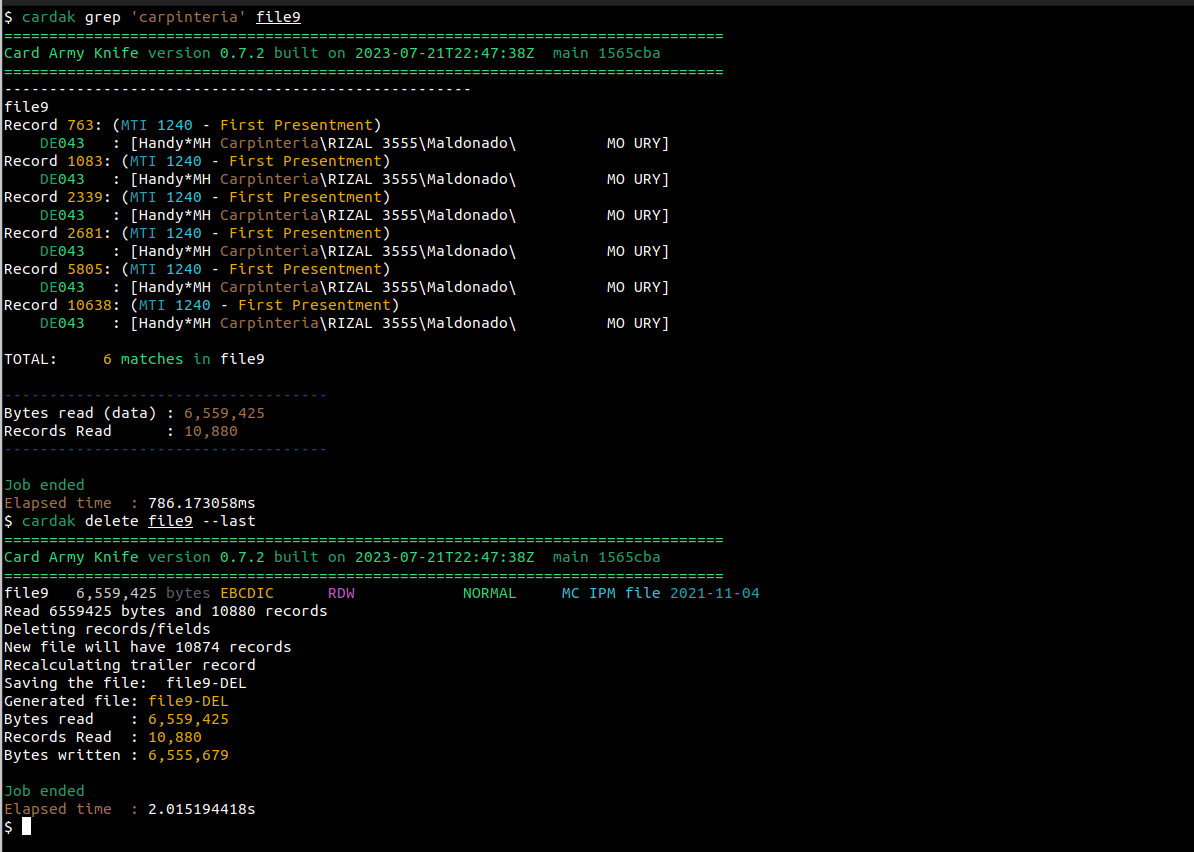
Realizamos una búsqueda por el valor “carpinteria”, y nos devuelve que hay 6 registros para ese comercio.
El próximo comando utilizado es el comando DELETE, pero usando el flag --last, por lo que se utiliza la lista de registros devueltas como resultado del GREP anterior, y vemos que efectivamente se genera un archivo con 10874 registros resultantes de quitar 6 registros de los 10880 originales.
Eliminar campos en algunos registros
También puede que necesitemos eliminar solo algunos campos de algunos registros, por ejemplo si por error incluimos algún campo que no debería viajar.
En forma similar al caso anterior, simplemente debemos agregar el flag -F con la lista de los campos que deseamos eliminar. Esos campos van a ser eliminados solamente de los registros indicados, o de todo el archivo en caso de no especificar ningún registro en particular.
Podemos indicar el o los registros donde queremos eliminar esos campos mediante el flag -F
Hay que tener cuidado ya que no se chequea que estemos borrando algún campo mandatorio.
Pasar registros de un archivo a otro
Digamos que queremos transferir registros de un archivo a otro. Esto lo podemos conseguir mediante dos pasos, primero, quitando los registros del primer archivo y luego agregándolos al segundo archivo.
El primer paso se consigue con el comando EXPORT, y el segundo con el comando IMPORT
Para el comando EXPORT tenemos dos opciones, exportar a un archivo CSV o una archivo HEX. Ambos formatos se pueden usar para la importación, aunque el formato HEX se considera una forma mas directa de pasaje.
Primero, vamos a seleccionar los registros que queremos exportar. Utilizaremos nuevamente el ejemplo anterior de los registros correspondientes al comercio “Carpinteria”:
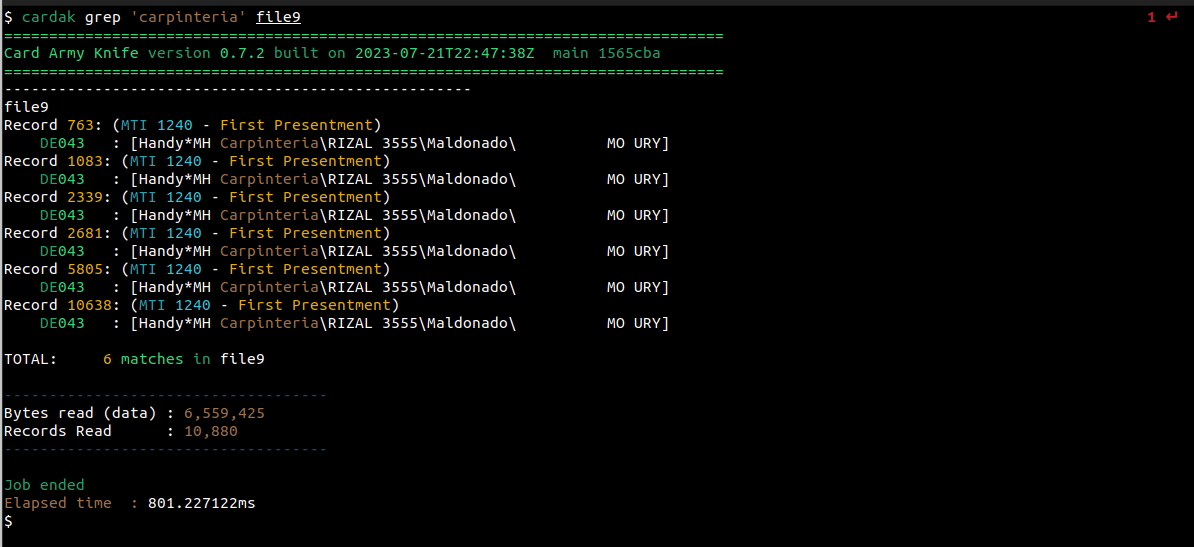 A continuación, procederemos a exportar esos registros a un archivo en formato HEX:
A continuación, procederemos a exportar esos registros a un archivo en formato HEX:
 Luego, importaremos esos registros al archivo file14 que como vemos, contiene 61 registros:
Luego, importaremos esos registros al archivo file14 que como vemos, contiene 61 registros:
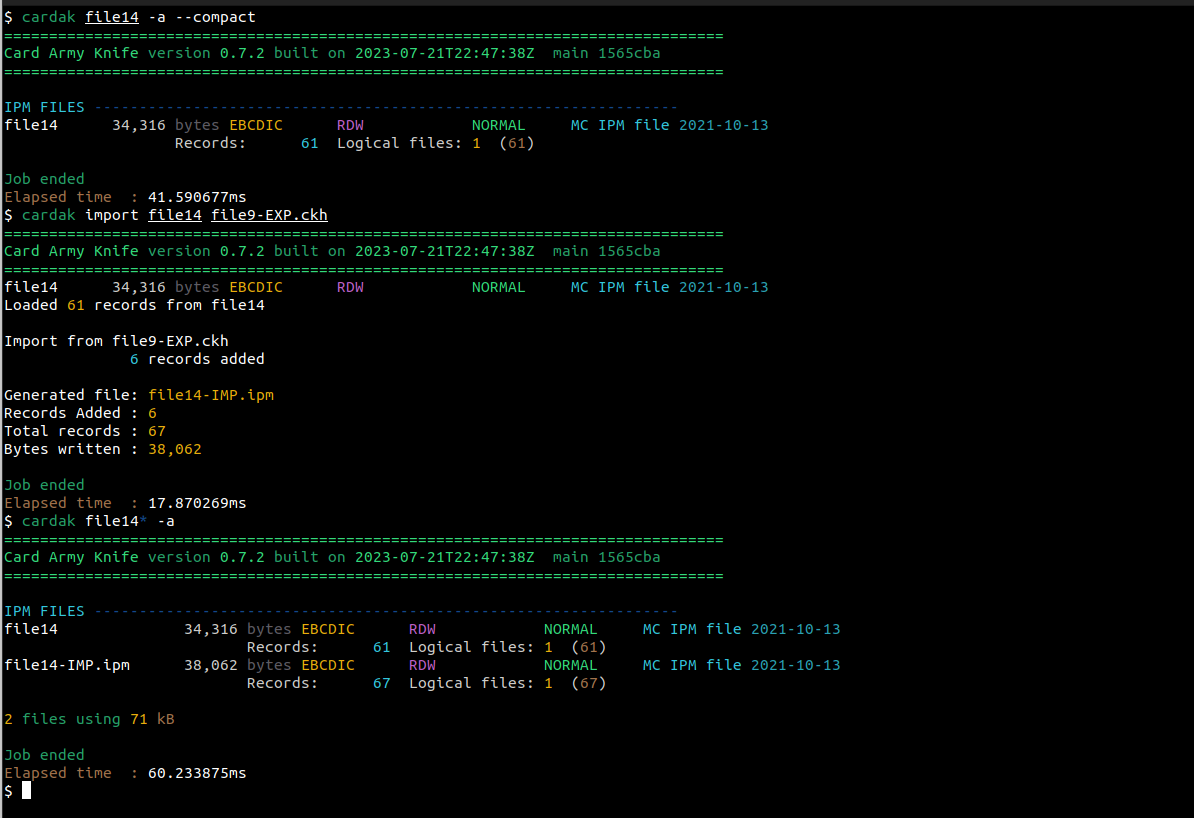 Observamos que se genera un nuevo archivo llamado file14-IMP.ipm que ahora contiene 67 registros, que son los 61 originales mas los 6 importados.
Observamos que se genera un nuevo archivo llamado file14-IMP.ipm que ahora contiene 67 registros, que son los 61 originales mas los 6 importados.