DISTRIBUTE
Distribuye registros de un archivo en múltiples archivos de salida según criterios específicos.
Sintaxis
$ cardak help distribute
usage: cardak distribute [<flags>] <files>...
Separate one IPM file into serveral ones by a given criteria.
By defining a criteria configuration file, the contents of an IPM file can be distributed across multiple files where each file contains records for each
criteria.
Sub_commands:
Instead of an IPM file, you can write "list" to show all defined criteria, or you can
specify the criteria name to display how it is configured.
Example:
cardak distribute list -> to show all existing definitions
cardak distribute <defname> -> Show the definition for <defname>
Flags:
--help Show context-sensitive help (also try --help-long and --help-man).
-v, --verbose Add more information displayed on some commands.
--mono Supress color on output.
--ignore Try to ignore some errors and continue processing the file
-W, --width Ignore small terminal width check and force execution
-z, --silent Suppress all output (banner, headers, summary) except the results. Specially useful for DESCRIBE command piped to a search
utility like fzf
-T, --file-type=FILE-TYPE Filter by file type when supplying several files. File types are represented by a single letter as: I-IPM files, M-MPE files
-c, --config=CONFIG Configuration file to use, otherwise it uses the default one
--delete Remove the given configuration
--dry Dry-run, simulate the process but do not create any files
--keep Do now delete empty generated files
-L, --load Load the given configuration for later use. It the configuration already exists, it will be replaced
-U, --unload Create a local version of the given configuration
Args:
<files> List of files. This can be a single file or you can use wildcards
Descripción
Este comando permite clasificar y distribuir registros de un archivo IPM en diferentes archivos de acuerdo a reglas definidas. Esto nos puede servir si, por ejemplo, recibimos un archivo de la marca que contiene transacciones que debemos a su vez enviar a diferentes procesadores, pero esas transacciones vienen todas juntas en un mismo archivo, y queremos que cada procesador reciba solamente las transacciones que les corresponden. O también, si quisiéramos generar archivos que contengan presentaciones, y por otro lado archivos que contengan registros de Fee collection.
Para poder ejecutar este comando, debemos tener archivos de configuración donde indicaremos los criterios a utilizar para esa clasificación de los registros.
Podemos ver la lista de archivos de configuración con el comando “cardak distribute list”
Hay dos ubicaciones posibles para estos archivos, o bien en la carpeta local, o en la carpeta “HOME” de la aplicación. Para copiar el archivo en la carpeta HOME, podemos utilizar el flag --load como veremos mas adelante.
Los archivos de configuración son archivos en formato JSON y su “esqueleto” es el siguiente:
{
"<ID>": {
"FileName": "File1",
“FilePattern”: “$B₁.$E”,
“Directory”: “/usr/dir/”,
"Description": ""
"ProcessorID": "123456789",
"FileSequence": 1,
"BinRanges": [
{
"BinMin": 0,
"BinMax": 9999
}
],
"MtiList": {
"1240": true
"1442": true
"1644": true
"1740": true
},
"FieldValues": "DE49:858"
}
}
Veamos en detalle como funciona esto:
En el primer nivel del JSON, vamos a colocar entradas, una por cada archivo que vamos a generar. A cada una de estas entradas debemos asignarle un nombre (que vemos como '<ID>' pero que puede ser cualquier nombre como veremos en un ejemplo posterior).
Para cada entrada, podemos definir el nombre del archivo (“FileName”), una descripción opcional (“Description”), así como un “ProcessorID” y un “FileSequence” que serán utilizados para crear el cabezal del archivo. Esto porque todos los registros que cumplan las condiciones van a ser guardados en un nuevo archivo, y en su cabezal, en el campo PDS0105, necesitamos algunos datos. El SF01 (File Type) es copiado del archivo original, y lo mismo sucede con el SF02 (File Reference Date).
Los archivos generados se generaran con un nombre de acuerdo a las siguientes reglas:
Si el campo FilePattern no esta presente, los archivos tendrán como nombre el del archivo original (sin la extensión), seguidos por el guion bajo “_” mas el string indicado en la entrada FileName y la extensión “.ipm”
Si indicamos un FilePattern, que es un string que contiene una combinacion opcional de tokens y caracteres que es utilizado como un patron para armar el nombre del archivo correspondiente.
Los tokens que se pueden utilizar son:
$B -> nombre base del archivo de entrada (nombre sin la extension)
$E -> extensión (sin el punto separador)
$D[YYYYMMDD] -> fecha/hora usando las siguientes definiciones
YYYY, YY, MM, DD, hh, mm, ss
$F[start:end] -> partes del nombre base (basados en runas). Valores negativos se cuentan desde el final hacia atrás
start comienza con el valor 0 y end indica el numero de caracter con cota superior, pero queda
excluido del rango.
Se aceptan omitir los extremos start y end
Ejemplos:
"ABCDEFGH" no da $F[2:4] -> "CD"
"ABCDEFGH" no da $F[:4] -> "ABCD"
"ABCDEFGH" no da $F[4:] -> "EFGH"
$F[-N] -> últimos N caracteres del nombre base
$F[N] -> primeros N caracteres de la base
$F[N$] -> últimos N caracteres de la base (alias a $F[-N])
$$ -> signo de pesos literal
Ejemplos:
FilePattern: “$F[:7]_DATA_$D[YYYYMMDD]-$F[7:].$E”
(Siete primeros caracteres) + "_DATA_" + (Fecha en formato YYYYMMDD) + "-" + (caracteres desde la posición 8 al final) + "." + (extensión)
Dados estos datos: Nombre de archivo = TT112T0abcdefghijkls.ipm, Fecha=2025-09-27
→ TT112T0_DATA_20250927-abcdefghijkls.dat
Si indicamos un directorio, el archivo sera generado en dicha ubicación. En caso de no existir el directorio, la herramienta intentara crearlo, fallando si por ejemplo, el usuario no tiene permisos de creacion. Pero el campo SF03 (Processor ID) y SF04 (File Sequence Number) son los indicados en estas entradas.
A continuación se especifican las condiciones que debe cumplir un registro para ser incluido en este archivo. Esas condiciones son rango de bines, MTI, o un valor de cualquier campo del registro. Estas condiciones son opcionales, pero debe existir al menos una de ellas.
El rango de bines consiste en una lista de pares Mínimo y Máximo, y si el BIN del campo DE002 se encuentra en alguno de esos rangos se considera valido (de todos modos se tienen que cumplir TODAS las condiciones especificadas). No se toma ningún largo de BIN especifico, sino que se considera el mínimo y el máximo para determinar la cantidad de caracteres a tomar del PAN para la comprobación.
También podemos indicar que valores de MTI debemos considerar para que el registro sea incluido en este archivo.
Por ultimo, podemos aplicar la regla “FieldValues”, donde lo que colocamos es una lista de campos y su valor, con las mismas reglas que utilizamos para las búsquedas del comando GREP (o sea, una lista de campo:valor separados por comas o punto y coma)
Para ver las configuraciones existentes, podemos utilizar el parámetro “list” de esta forma:
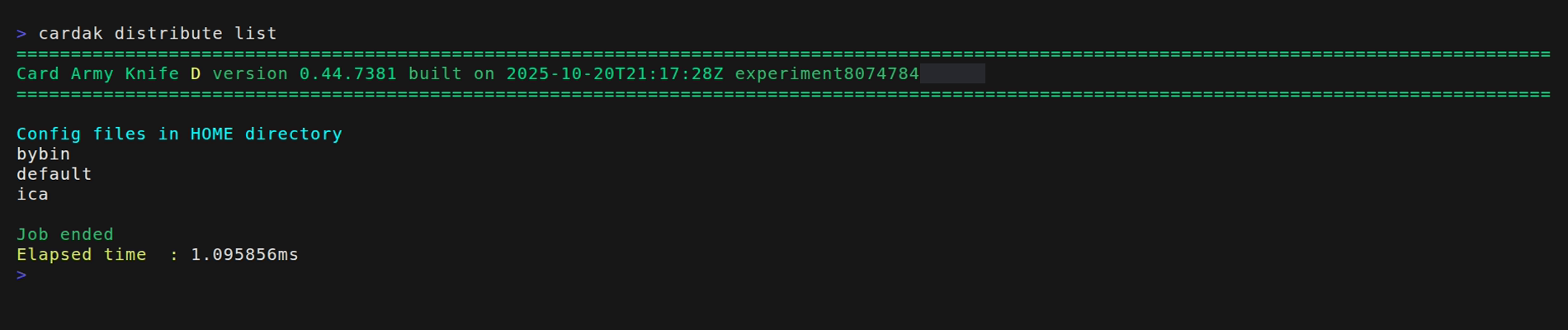
Vemos que tenemos dos configuraciones cargadas. La llamada “default” esta siempre presente y es la que se va a utilizar si no especificamos ninguna.
Para ver el contenido de las definiciones, podemos agregar el flag -v o especificar el nombre de la configuración que queremos ver
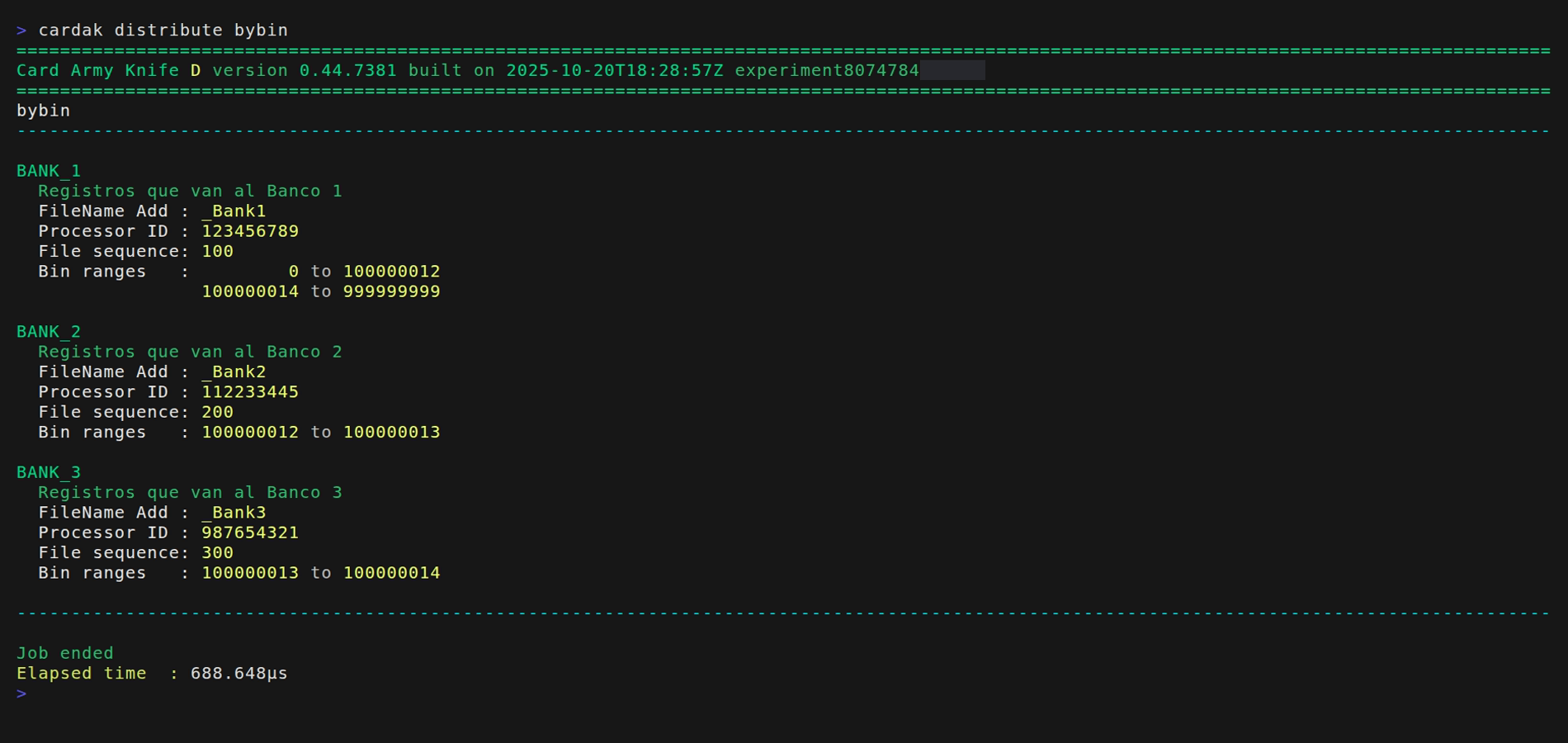
Veamos un ejemplo practico y sencillo. Queremos separar las transacciones de un archivo en dos archivos de tal forma que todas las transacciones en Dólares vayan a un archivo y las que sean en Pesos vayan a otro.
Para ello, vamos a crear un archivo llamado “money_dist.json” y le colocaremos este contenido:
{
"1-PESOS-858": {
"FileName": "pesos",
"FilePattern": "$F[:7]_PESOS_$F[7:].$E",
"Description": "Registros en Pesos Uruguayos",
"ProcessorID": "123456789",
"FieldValues": "D49:858"
},
"2-DOLARES-840": {
"FileName": "dolares",
"FilePattern": "$F[:7]_DOLARES_$F[7:].$E",
"Description": "Registros en Dolares",
"ProcessorID": "987654321",
"FieldValues": "D49:840"
}
}
Con esto estoy indicando que voy a generar dos archivos, uno cuyo nombre va a ser “pesos” y algo mas, y el otro que sea “dólares” (y algo mas que ya veremos).
Dentro de cada uno, van a tener el ProcessorID indicado, pero no voy a especificar ningún FileSequence por lo que se va a utilizar el mismo del archivo original.
Respecto a las condiciones, no voy a utilizar ni los rangos de bines ni los MTI, pero si le indico que para el archivo con transacciones en pesos, el valor del campo DE049 debe contener el valor 858, y para el caso de dólares el valor 840 Veamos las configuraciones disponibles
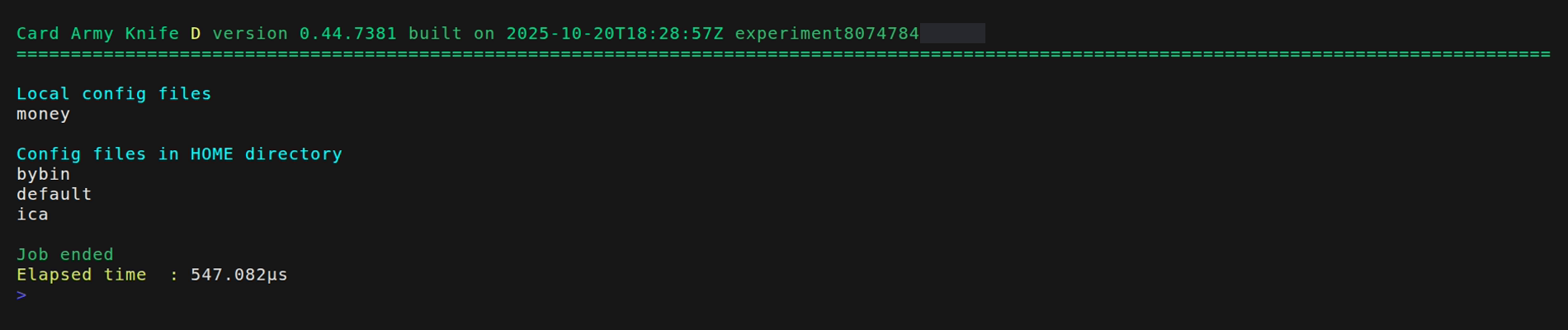
Ya que no resulta practico dejar la configuración en el directorio local, vamos a cargarlo en el HOME de la aplicación. Para ello utilizaremos el flag --load
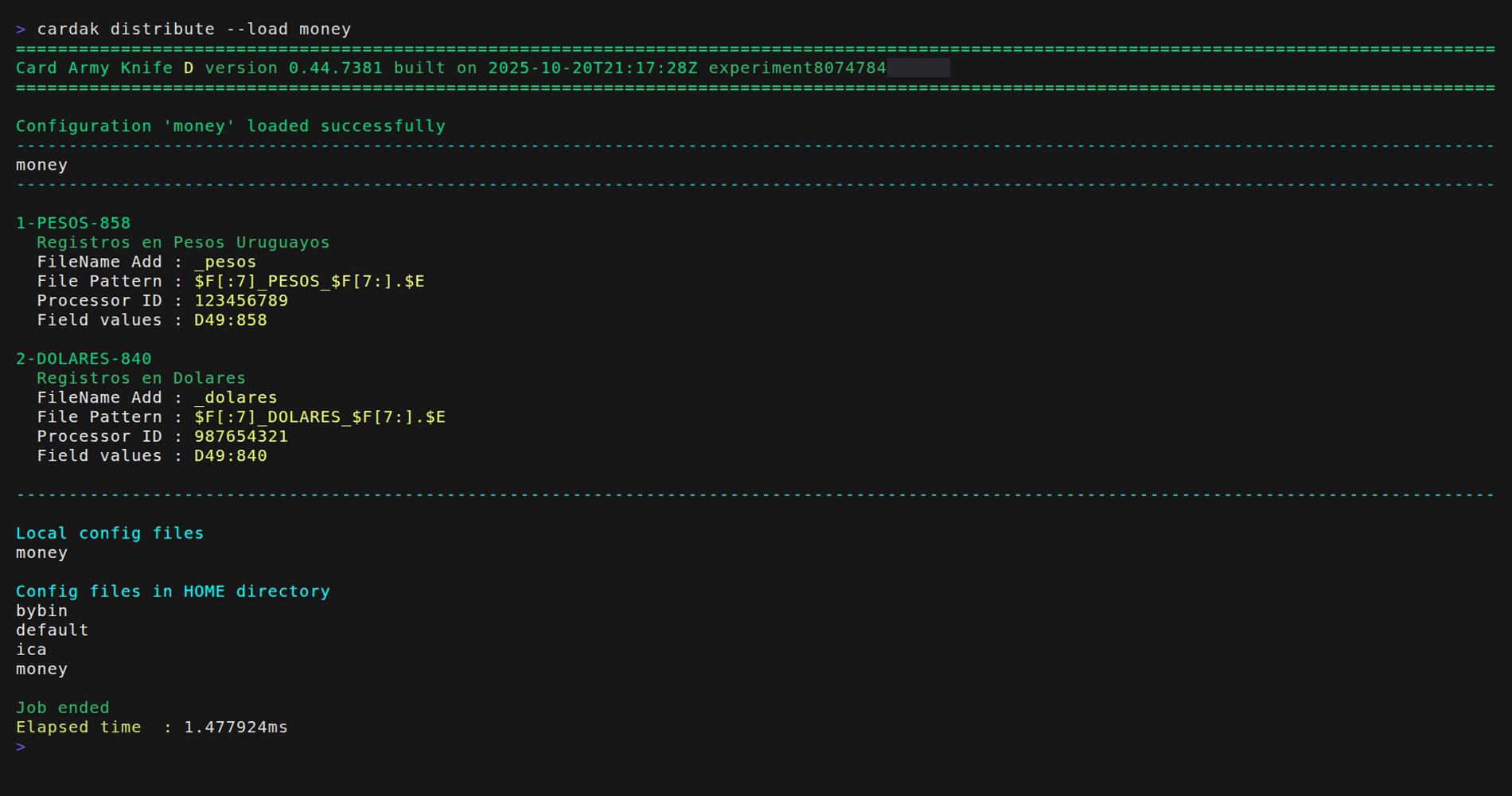
Y ahora podemos borrar el archivo local “money_dist.json”, pero la configuración quedara disponible a través de su copia en el directorio HOME. Si la misma configuracion esta presente en el directorio local y en el HOME, tiene precedencia la local.
Para utilizar este comando, debemos indicar el nombre del archivo a separar y, opcionalmente, el nombre de la configuración que queremos aplicar.
Si no especificamos ningún nombre de configuración, la herramienta va a intentar localizar una configuración llamada “default”. Esto es útil si tenemos una configuración que utilizaremos por defecto a fin de evitar especificarla en cada ejecución.
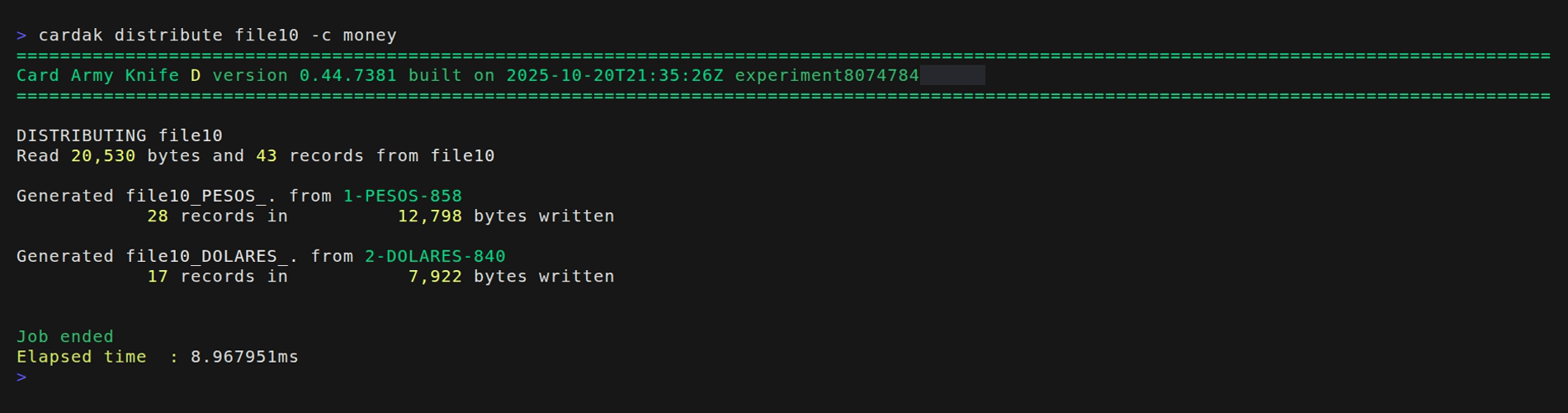
En este caso tomaremos los contenidos del archivo file10. Primero vamos a realizar una simulación y para ello agregamos el flag --dry (este paso es opcional, lo utilizaremos como demostración y pruebas)
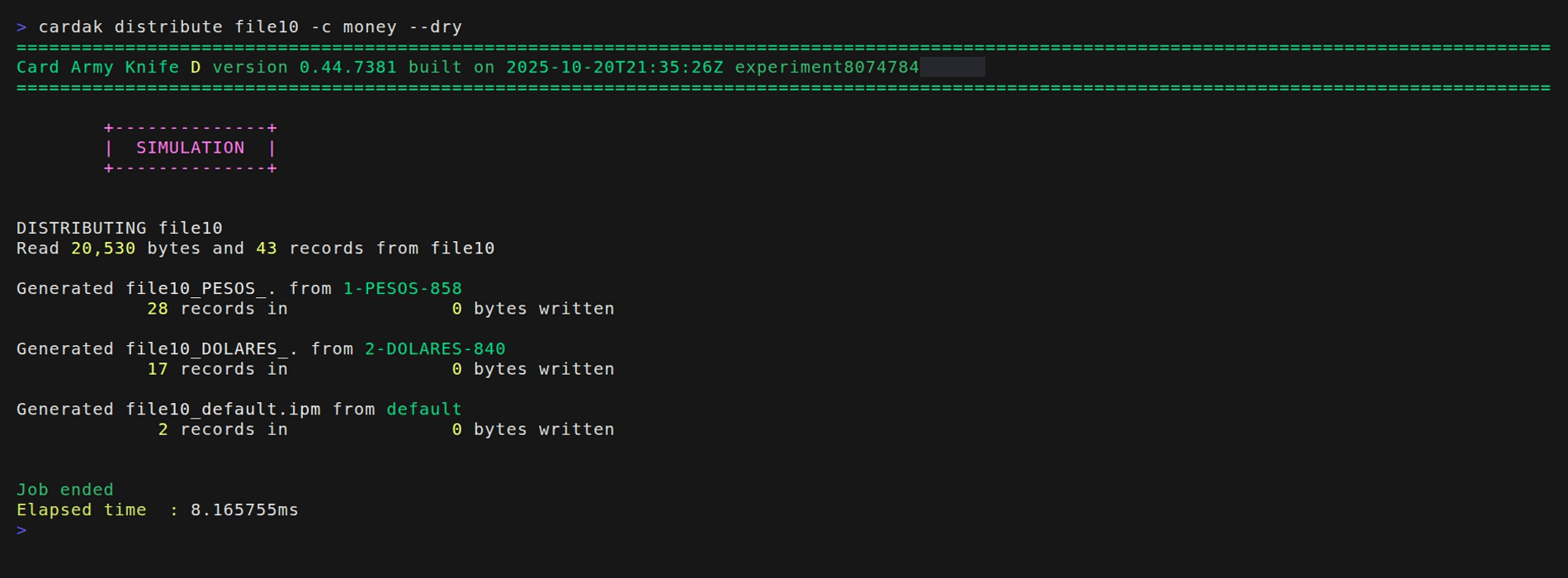
El flag --dry ejecuta una simunacion, por lo que no se escriben los archivos de salida, pero se muestran los archivos que se hubieran generado y la cantidad de registros en cada uno.
El proceso va a tomar los 43 registros del archivo file10, y va a crear un archivo con los 28 registros en pesos, y otro con los 17 registros en dólares.
Vemos la aparición de un tercer archivo llamado “default”. Este seria el archivo a generar con todos los registros que no cumplan con ninguna de las condiciones.
En este caso, como no hay ningún registro que no las cumpla, se estaría generando un archivo llamado “default” que contiene solo un header y un trailer, por lo que en realidad ese archivo no se genera porque estaría vacío, solo se muestra en la simulación. Si quisiéramos generarlo de todo modos, bastaría con agregar el flag --keep
Para generar los archivos, omitimos el flag --dry